MySQL High Availability Setup: DRBD, Pacemaker, Corosync
 (Toplam 5 oy. 5 puan üzerinden ortalama 5,00 || Oy vererek siz de katkıda bulunabilirsiniz.)
(Toplam 5 oy. 5 puan üzerinden ortalama 5,00 || Oy vererek siz de katkıda bulunabilirsiniz.)Kritik noktalarda çalışan MySQL servislerinde, yüksek erişilebilirlik sağlamak (high availability) ve herhangi problem anında mümkün olan en kısa sürede otomatik olarak tekrar servis verebilir duruma gelmek için uygulamanızın özelliklerine ve altyapınıza göre replikasyondan clustering’e birden fazla alternatif kullanabilirsiniz. Böyle bir ihtiyaç için seçilebilecek alternatiflerden birisi DRBD/Pacemaker/Corosync üçlüsünü kullanarak active/passive olmak üzere iki node’dan oluşan bir HA cluster kurmak olabilir.
Bu tip bir yapı ile http://dev.mysql.com/doc/refman/5.0/en/ha-drbd.html adresinde de anlatıldığı üzere iki adet (fiziksel ya da sanal) sunucu ile ortak bir storage vs. gibi herhangi ek bir yatırıma gerek kalmadan otomatik failover ve recovery özelliği ile servis devamlılığı ve senkron replikasyon (mirroring) yaparak data güvenliği sağlayan bir yapı elde edebilirsiniz.
Yazının devamında böyle bir yapının CentOS 6.5 ve MySQL 5.1 kullanılarak oluşturulmasına ait kurulum notlarını paylaşacağım.
İçerik İndexi
MİMARİ ve BİLEŞENLER
Doğrudan yapılması gerekenlere girmeden önce konuya daha iyi hakim olunabilmesi açısından bileşenlerin neler olduğundan ve bunları neden hangi amaçla kullandığımızdan bahsetmek istiyorum. Zira bu tip bir MySQL HA yapısı çok komplike olmasa da söz konusu olan yüksek erişilebilirlik, kümeleme vs. olduğunda iş ister istemez komplikeleştiği için konuya hakim olunması elzem bir durum halini alır.
Yukarıda linkini verdiğim dökümanda, yapının nasıl olduğunu gösteren şu şekilde güzel bir şema var:
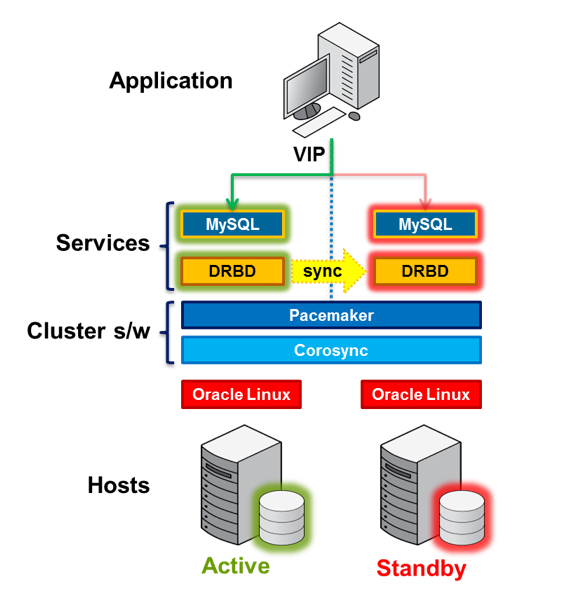
Şemada anlatılan yapıda, temel olarak iki host’unuz bulunuyor ve her iki host’ta da detaylarını aşağıda açıklayacağım şekilde clusterımızın bileşenleri olan MySQL, DRBD, Pacemaker ve Corosync servislerini kuruyoruz. Nodelardan birisi Master (Active), diğeri Slave (Standby) modda çalışıyor. VIP diye gösterilen Virtual IP, Master host üzerinde bulunuyor ve uygulama bu VIP üzerinden Master node’da bulunan MySQL’e erişiyor. Master üzerindeki diske yazılan çizilen herşey ise beklemedeki slave node’a sync ediliyor. Master’a bir şey olması durumunda standby’da bekleyen node kendini Master olarak set ediyor ve VIP’yi üzerine alıyor. Disk durumları iki node arasında sync olduğundan dolayı da MySQL üzerinde herhangi data kaybı olmaksızın MySQL hizmeti saniyeler içinde ikinci host üzerinden verilmeye devam ediyor.
Teorik cluster’ın çalışma prensibi kabaca yukarıdaki gibi özetlenebilir ancak elbette iki host üzerindeki disklerin birbiri ile sync olması, problem anlarında slave’in kendisini master olarak set edip VIP’i üzerine alması gibi olayların tam olarak nasıl cereyan ettiğini anlamak için cluster bileşenlerinden ayrıca bahsetmek yerinde olacaktır, bu şekilde büyük resmi görmeniz daha da kolaylaşacaktır sanıyorum.
DRBD
Açılımı “Distributed Replicated Block Device” olan DRBD temel olarak network üzerinden iki disk (storage) arasında block level’da replikasyon yapmaya yarayan kendi deyimleri ile “software-based, shared-nothing, replicated storage” çözümüdür. DRBD, iki host üzerindeki birbirinden bağımsız storage’lar arasında network üzerinden replikasyon yapmanızı sağladığından dolayı datanızı iki host üzerinde identical bir şekilde tutmanızı sağlıyor. “Network based raid-1” de denilen bu çözüm ile iki hostun ilgili block deviceları arasında mirroring yapılıyor.
Konuyu bir örnekle açıklamak gerekirse A ve B isimli iki host’umuz olduğunu ve bu iki host üzerinde ikinci birer diskimiz olduğunu (ki ayrı bir disk yerine bir LVM logical volume ya da partisyon da kullanabiliriz) ve bu ikinci disklerin /dev/sdba ismine sahip olduklarını düşünelim. DRBD yapılandırmasında host A’yı primary olarak belirlediğimizde bu host üzerindeki block device (örneğimizde /dev/sdba) B hostundaki aynı isimli block device’a simetrik olarak replike edilir.
DRBD block levelda senkronizasyon yaptığından dolayı ilgili disk üzerinde ne data olduğu ile ilgilenmez, tek yaptığı block block A hostundaki /dev/sbda diskindeki veriyi uzak B hostundaki /dev/sdba diskine senkronize etmektir. Senkronizasyon işlemi primary diske herhangi bir şey yazılıp çizildiği an gerçekleştiği için real timedır ve block level mirroring olduğu için gerçekten çok hızlı cereyan eder.
Bu yazıda da buna benzer şekilde iki sunucumuz olacak ve sunuculara ikinci birer disk takacağız ve disklerden primary olanın diğerine sync edilmesini sağlayacağız. Tahmin edebileceğiniz gibi primary diskte mysql data’yı barındıracağız ve bu data DRBD sayesinde her iki hostta da güncel ve identical olarak erişilebilir olacak. Böylece primary hostta herhangi bir arıza meydana gelmesi durumunda mysql servisinin otomatik olarak ikinci host üzerinden devam ettirilmesini sağlayacağız.
DRBD’nin çalışma prensibini gösteren şu şema konunun daha iyi anlaşılmasına yardımcı olacaktır.
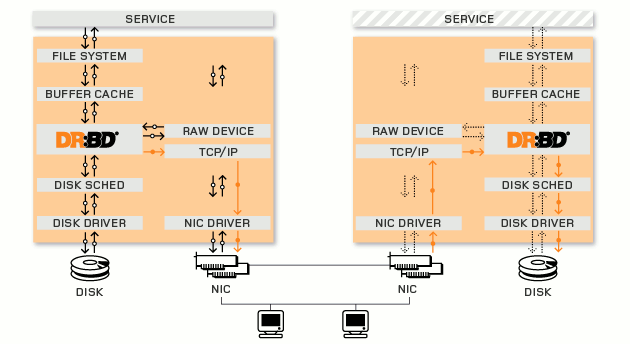
Yazının ilgili bölümününde yapılandıracağımız DRBD ile ilgili bu kadar bir teorik girizgah yeterli olacaktır ancak konunun derinlerine inmek isterseniz http://www.drbd.org/ adresine göz atabilirsiniz.
Pacemaker
MySQL Cluster’ımızda kullanacağımız diğer iki önemli bileşen ise cluster’ı oluşturan hostların (ki biz bundan sonra bunlara node diyelim) durumlarından hareketle ilgili node’ların ya da node’lar üzerinde çalışan uygulamaların – örneğimizde MySQL- start/stop edilerek cluster’ın sorunsuz servis vermeye devam etmesini sağlayan pacemaker ve corosync ikilisidir.
Detaylarına http://clusterlabs.org/doc/en-US/Pacemaker/1.1-crmsh/html/Pacemaker_Explained/index.html adresinden erişebileceğiniz Pacemaker cluster’ı oluşturan nodeları ve servislerin yönetiminden sorumlu olduğundan dolayı bir orchestrator gibi çalışarak cluster’ın beynini oluşturmaktadır.
Corosync
Corosync node’lar arasındaki iletişimin sağlanmasından sorumlu bileşendir ve Pacemaker’a bir messaging interface sağlar. Bu şekilde pacemaker node’ların ve node’lar üzerindeki servislerin ne durumda olduğundan haberdar olarak aksiyon alabilmektedir. Corosync ile ilgili detaylı bilgi için http://corosync.github.io/corosync/ adresine göz atabilirsiniz.
ÖRNEK SENARYO
Cluster’ı oluşturacak temel bileşenlere girizgah seviyesinde değindikten sonra, bu yazıda MySQL HA yapısında neler olacağını ve nasıl uygulanacağını bir senaryo çerçevesinden çizmek iyi olacaktır.
Ben bu senaryoda
- node01.crom.lab (10.1.1.101) ve node02.crom.lab (10.1.1.102) isimli iki adet host kullanacağım,
- Ayrıca, birim zamanda master olan hosta atanacak “Virtual IP” 10.1.1.100 olacak.
- Her iki host üzerinde de MySQL, DRBD, Pacemaker ve Corosync paketleri kurulu olacak.
- Hostların her ikisinde de /dev/sdb isimli ikinci bir disk bulunacak ve /dev/sdb diski DRBD ile iki host arasında sync tutulacak.
- Master olan host üzerindeki /dev/sdb diski /mysql_drbd dizinine mount edilecek.
- MySQL server’ın conf (my.cnf) ve data dizini /mysql_drbd altında olacak. Bu şekilde DRBD üzerinden diğer hosta sürekli sync edilecek.
- Master’ın down olması durumunda, slave üzerinde bulunan pacemaker diğer hostun down olduğunu corosync üzerinden yapılan mesajlaşma sonucu anlayıp kendi /dev/sdb diskini kendi /mysql_drbd dizinine mount edip, virtual IP’yi kendi üzerine alacak ve MySQL servisini başlatacak.
Temel olarak MySQL HA senaryomuz bu şekilde. Zannediyorum ki teoriden yeteri kadar bahsettik, bu nedenle artık konunun pratiğine geçebiliriz.
KURULUM
Kurulum sırasında bazı işlemler her iki hostta da bazıları ise sadece tek bir hostta yapılacak. Bu nedenle işlem adımlarında bu durumu ayrı ayrı bildireceğim. İşe, öncelikli olarak nodelar üzerindeki hostname, selinux, iptables vs. gibi temel düzenlemeleri yaparak başlayacağız.
 |
NOT: Kurulım adımlarından herhangi birini atlamak ya da hata yapmak cluster’da genel problemlere neden olabileceği için tüm işlemleri dikkatli yapmanızı öneririm. |
Hostname
Cluster yapısında node’ların birbiri ile düzgün irtibatı olmazsa olmaz bir konudur. Bu nedenle temel olarak node’ların düzgün birer hostname’i olmalı ve birbirlerini hostname ya da FQDN ile çözebilir olmalıdırlar.
Bu sebeplerden dolayı, hostların her ikisinde de hostname ve hosts tanımlamalarını yapıyoruz.
node01:
# hostname node01 # sed -i '/HOSTNAME=/c\HOSTNAME=node01' /etc/sysconfig/network # echo 10.1.1.101 node01 >> /etc/hosts # echo 10.1.1.102 node02 >> /etc/hosts
node02:
# hostname node02 # sed -i '/HOSTNAME=/c\HOSTNAME=node02' /etc/sysconfig/network # echo 10.1.1.101 node01 >> /etc/hosts # echo 10.1.1.102 node02 >> /etc/hosts
Bu şekilde her iki node birbirlerini isimden çözebilecek duruma geleceklerdir. Tanımlamaların doğruluğundan karşılıklı olarak birbirlerini isimlerinden pingleyerek emin olun.
IPTables ve SELinux
Normalde gerekli portlara gerekli izinleri vererek iptables kullanılabilir ancak işleri karmaşıklaştırmamak için ben mysql node’larda iptables ve Selinux’u disable ediyorum:
Her iki Host’ta da:
# > /etc/sysconfig/iptables # chkconfig iptables off && chkconfig ip6tables off # setenforce 0 # sed -i '/SELINUX=/c\SELINUX=disabled' /etc/selinux/config
YUM Repo`ları
DRBD kernel modülü’nü ve pacemaker crmsh paketlerini farklı repolardan alacağız. Bu nedenle bu repoları yum’a tanıtalım:
Her iki node’da:
# rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm # rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org; rpm -Uvh http://www.elrepo.org/elrepo-release-6-5.el6.elrepo.noarch.rpm
Paketlerin Yüklenmesi
Şimdi drbd, pacemaker ve corosync paketlerini kuruyoruz.
Her iki node’da:
# yum install drbd84-utils kmod-drbd84 corosync pacemaker
İlgili paketleri yükledikten sonra her iki hostu da reboot edelim. (Aslında buna çok gerek yok ancak özellikle drbd kernel modülü için bu reboot’u gerekli görüyorum.
# reboot
YAPILANDIRMA
Bundan sonraki aşamada öncelikle, iki host arasında sync edeceğimiz diskler için drbd tanımlamalarını yapacağız. Ardından her iki hosta MySQL kurulumu yapıp data dizininin drbd üzerinden sync edilen diskte tutulmasını sağlayacak konfigurasyonu yapacağız. En sonda ise pacemaker ve corosync yapılandırmasını tamamlayacağız.
DRBD Yapılandırması
Bu işlem için “Örnek Senaryo” kısmında da değindiğim gibi her iki host üzerinde ikincil bir disk olması gerekiyor. (zira DRBD block level’da senkronizasyon yaptığı için bir block device’a ihtiyacınız var.) Benim test için kullandığım hostlarda bu disk /dev/sdb şeklinde takılı durumda.
Yapılandırma sırasında bu diski olduğu gibi kullanabileceğiniz gibi, LVM tanımlaması yapıp oluşturacağınız logical volume’ün sync edilmesini sağlayabilirsiniz. LVM kullanmanın online resize, snapshot vs. gibi avantajlarından dolayı ben bu yolu tercih ediyorum. Bu nedenle şimdi her iki host üzerinde de LVM yapılandırmasını tamamlamamız gerekiyor.
Her iki node’da:
# pvcreate /dev/sdb # vgcreate vgdrbd /dev/sdb # lvcreate -l 100%FREE -n lvmysql vgdrbd
Yukarıdaki komut serisi ile, /dev/sdb kullanan bir pv‘miz, “vgdrbd” isimli bir volume grubumuz ve “lvmysql” isimli bir logical volumümüz olmuş oluyor.
Şimdi her iki hostta da oluşturduğumuz bu logical volume’ün DRBD üzerinde sync edilmesi için gerekli konfigurasyonu yapalım.
Öncelikle, /etc/drbd.d/ dizini altında clusterdb.res isimli bir dosya açın:
Her iki node’da:
# vi /etc/drbd.d/clusterdb.res
Dosya içerisine aşağıdaki ibareleri ekleyin ve “kırmızı ile belirtilen yerleri kendinize göre düzenleyin”.
resource clusterdb {
protocol C;
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
}
startup {
degr-wfc-timeout 120;
outdated-wfc-timeout 2;
}
disk {
on-io-error detach;
}
net {
cram-hmac-alg "sha1";
shared-secret "sifre-buraya";
after-sb-0pri disconnect;
after-sb-1pri disconnect;
after-sb-2pri disconnect;
rr-conflict disconnect;
}
syncer {
rate 20M;
al-extents 257;
on-no-data-accessible io-error;
}
volume 0 {
device /dev/drbd0;
disk /dev/vgdrbd/lvmysql;
meta-disk internal;
}
on node01 {
address 10.1.1.101:7788;
}
on node02 {
address 10.1.1.102:7788;
}
}
Bu konfigurasyonla, drbd’ye /dev/drbd0 isimli sanal bir block device yaratmasını ve /dev/vgdrb/lvmysql isimli logical volumumuze map ederek bu LV’ye yazılıp çizilecek herşeyi karşı hosttaki aynı sanal device’a (dolayısı ile aynı logical volume’e) sync etmesini söylemiş oluyoruz.
Yapılandırma opsiyonlarının neler olduğuna uzun uzadıya girmek isterdim ama konuyu daha çok karmaşıklaştırmamak adına girmeyeceğim. Parametrelerin anlamlarını merak ederseniz http://www.drbd.org/users-guide/ adresine göz atmanızı tavsiye ederim.
Şimdi yapılandırmamızın devreye alınması ve yukarıda bahsettiğim /dev/drbd0 isimli virtual device’ın oluşturulması için her iki hostta da sıra ile aşağıdaki komutu çalıştıralım.
Her iki node’da (sıra ile):
# drbdadm create-md clusterdb
Bu komutu verdiğiniz zaman DRBD, /etc/drbd.d/ dizini altındaki .res uzantılı dosyanızı okuyacak ve dosyada belirtilen düzenlemeyi yapacaktır.
Writing meta data... initializing activity log NOT initializing bitmap New drbd meta data block successfully created. success
Şimdi, drbd’yi her iki hostta da sıra ile start edelim:
Her iki node’da:
/etc/init.d/drbd start
Drbd sorunsuz bir şekilde start edildiğinde aşağıdaki gibi bir çıktı alırsınız.
Starting DRBD resources: [
create res: clusterdb
prepare disk: clusterdb
adjust disk: clusterdb
adjust net: clusterdb
]
.
ve bahsi geçen /dev/drbd0 isimli virtual device her iki host’ta da oluşturulacaktır.
# file /dev/drbd0 /dev/drbd0: block special
Ayrıca, “/etc/init.d/drbd status” komutu ile de her iki host üzerindeki drbd durumunu görebilirsiniz.
# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.4 (api:1/proto:86-101) GIT-hash: 599f286440bd633d15d5ff985204aff4bccffadd build by phil@Build64R6, 2013-10-14 15:33:06 m:res cs ro ds p mounted fstype 0:clusterdb Connected Secondary/Secondary Inconsistent/Inconsistent C
Yukarıda bold olarak belirtilen bölümlerden görebileceğiniz gibi şu anda connect durumda clusterdb isimli bir drbd resource’umuz bulunuyor. Ancak disklerin hostlar arası senkronizasyonu için hostlardan birisinin “Primary” olarak set edilmesi gerekiyor. Bu şekilde primary host üzerindeki diske yazılan çizilen herşey secondary hosta da replike edilebilecektir. Disklerin durumunun“Inconsistent/Inconsistent” olarak görülmesinin nedeni de budur. Zira, Primary disk olmadığından DRBD neyi nereye sync edeceğini bilememektedir.
Bu nedenle şimdi, node01’i Primary olarak belirleyeceğiz ve node01 üzerindeki diskin node02,ye de senkronize edilmesini sağlamak için aşağıdaki komutu node01 üzerinde çalıştıralım.
Sadece node01’da:
# drbdadm -- --overwrite-data-of-peer primary all
Bu komut, çalıştırıldığı node üzerindeki DRBD’ye kendisinin tüm resourcelar için Primary olmasını ve üzerindeki datayı diğer peer’e (node02) yazmasını söylemektedir.
Komutu çalıştırdıktan sonra, nodelardan herhangi birinin üzerinden /etc/init.d/drbd status komutu ile drbd’nin durumuna baktığınız zaman senkronizasyonun başlamış olduğunu görebilrsiniz.
Ben node01 üzerinden baktığım zaman şu şekilde görüyorum.
[root@node01 ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.4 (api:1/proto:86-101) GIT-hash: 599f286440bd633d15d5ff985204aff4bccffadd build by phil@Build64R6, 2013-10-14 15:33:06 m:res cs ro ds p mounted fstype ... sync'ed: 11.8% (18080/20472)M 0:clusterdb SyncSource Primary/Secondary UpToDate/Inconsistent C
Gene bold olarak belirilen satırdan anlayabileceğiniz gibi, node01 şu an Primary durumda ve karşıdaki node’a üzerindeki datayı sync etmeye başlamış durumda. Buradaki SyncSource ibaresi bu hostun sync için kaynak olduğunu belirtmektedir, Aynı duruma node02’den bakarsanız onun da SyncTarget olduğunu görebilirsiniz. Anlaşıldığı üzere, / ibaresinin sol tarafı statusune baktığınız drbd host’un kendisini, sağ tarafı ise uzak hostun durumu ile ilgili bilgi vermektedir.
Şimdi bu sync işleminin bitmesini bekleyeceğiz. Diskinizin büyüklüğüne ve aradaki networke göre bir iki dakika kadar sürebilir. Sync işlemi bittikten sonra yeniden drbd statuse göz attığımızda durumu aşağıdaki gibi görmemiz gerekmektedir:
[root@node01 ~]# /etc/init.d/drbd status drbd driver loaded OK; device status: version: 8.4.4 (api:1/proto:86-101) GIT-hash: 599f286440bd633d15d5ff985204aff4bccffadd build by phil@Build64R6, 2013-10-14 15:33:06 m:res cs ro ds p mounted fstype 0:clusterdb Connected Primary/Secondary UpToDate/UpToDate C
Görüldüğü üzere her iki disk’in durumu da UpToDate olarak güncellenmiş durumda. Dolayısı ile artık primary diske ne yazarsanız data aynı şekilde secondary’e de sync edilecek.
Gelinen noktada iki node üzerindeki /dev/sdb diskini içeren lvmysql isimli logical volume, /dev/drbd0 isimli virtual device üzerinden, block level da replike ediliyor. Ancak diskler üzerinde henüz bir dosya sistemi yok. (Replikasyon’un block level da yapılıyor olmasının espirilerinden birisi de bu; zira drbd için disk üzerinde bir dosya sistemi olup olmaması önemli değildir. O sadece diskA’yı block bazında diskB’ye kopyalamaktadır.)
Dolayısı ile şimdi node01 üzerindeki /dev/drbd0 diski üzerinde ext4 dosya sistemi oluşturalım: (Not: /dev/drbd0 = /dev/vgdrbd/lvmysql olduğundan drbd0’i formatlamak, ilgili logical volume’ü formatlamak anlamına gelmektedir):
Sadece node01’da:
# mkfs.ext4 /dev/drbd0
Bu aşamada DRBD ile ilgili yapılandırma tamamlanmış oluyor. Şimdi cluster’ın diğer bileşenlerina geçelim.
MySQL Kurulumu
MySQL kurulumunu her iki hosta da yapacağız, yani MySQL ile ilgili binary ve kütüphaneler her iki node üzerinde de bulunacak. Ben MySQL kurulumunu doğrudan CentOS’un base reposundan yapacağım. Ancak siz istediğiniz herhangi bir kaynaktan da kurabilirsiniz elbet:
Her iki node’da:
# yum install mysql-server -y
Şimdi de her iki hosta MySQL’in data dizini olacak /mysql_drbd isimli birer dizin yaratıyoruz:
Her iki node’da:
# mkdir /mysql_drbd # chown -fR mysql:mysql /mysql_drbd
Bundan sonra node01 üzerinde /dev/drbd0 diskimizi /mysql_drbd dizinine mount edip MySQL ile ilgili temel işlemleri yapacağız. Bu aşamada disk üzerinde yapılan her tür işlem node02’ye de replike edileceği için işlemler pratikte her iki host üzerinde de gerçekleşmiş olacak.
Sadece node01’da:
# mount /dev/drbd0 /mysql_drbd # mkdir /mysql_drbd/data # cp -pr /usr/share/mysql/my-large.cnf /mysql_drbd/my.cnf
Bu son işlemi özetlersek, drbd0 mysql_drbd dizinine mount edildi ve içerisinde, MySQL datamızı tutacağımız “data” isimli bir dizin oluşturuldu. (Bu değişiklik node02’ye de block levelda replike edildi.) Sonrasında da örnek bir my.cnf dosyası /mysql_drbd dizinine kopyalandı. (Bu değişiklik de node02’ye yansıtıldı.)
Yani bu durumda mysql_drbd dizini iki disk arasında sync tutulduğundan dolayı hem my.cnf dosyamız hem de data dizinimiz birim zamanda her iki host üzerindeki diskte de bulunacak. Biz Primary üzerindekinden işlem yaparkan aynı dataya problem olması durumunda Secondary üzerinden de erişebilir olacağız.
Şimdi node01 üzerinde mysql’e data dizininin yerini /mysql_drbd/data olduğunu söyleyelim. Bu işlem için my.cnf dosyamızı editliyoruz:
Sadece node01’da:
# vi /mysql_drdb/my.cnf
ve [mysqld] bölümünde aşağıdaki değişikliği yapalım:
datadir = /mysql_drbd/data # Ayrıca innodb kullanıyorsanız: innodb_data_home_dir = /mysql_drbd/data innodb_log_group_home_dir = /mysql_drbd/data
Not: Bu datadir ibaresi yoksa kendiniz ekleyebilirsiniz. Ayrıca, innodb kullanıyorsanız innodb ile ilgili innodb_data_home_dir ve innodb_log_group_home_dir gibi parametreleri de /mysql_drbd/data dizinini gösterecek şekilde düzenlemeyi unutmayın.
Şimdi, MySQL’i start etmeden, mysql db’sinin yeni dizine populate edilmesi için aşağıdaki komutu çalıştıralım:
Sadece node01’da:
# mysql_install_db --no-defaults --datadir=/mysql_drbd/data --user=mysql # chown -fR mysql:mysql /mysql_drbd/data # chmod -fR 755 /mysql_drbd/data
Bu işlemin ardından, /mysql_drbd/data dizininin içinde mysql ve test isimli db’lere ait dosyaları görebilirsiniz:
[root@node01 mysql_drbd]# ls -l /mysql_drbd/data/ total 8 drwx------ 2 mysql root 4096 Jan 29 18:36 mysql drwx------ 2 mysql root 4096 Jan 29 18:36 test
Şimdi MySQL ile ilgili işlemleri de bu şekilde tamamlamış oluyoruz. Ancak son olarak node01’de mount durumda olan /dev/drbd0’ı unmount edelim ve Primary olarak set edilmiş olan drbd resource’u Secondary olarak set ediyoruz:
Sadece node01’da:
# umount /mysql_drbd/ # drbdadm secondary clusterdb
Dikkat edersek MySQL’i start etmedik ve diski unmount edip drbd resource’u secondary yaptık. Çünkü yazının ilerleyen bölümlerinde diskin mount edilmesi, drbd’nin yönetilmesi ve MySQL’in start stop edilmesi işlerini Pacemaker’a yaptıracağız. Bu nedenle manual hiç bir iş yapmıyoruz.
Corosync Yapılandırması
Yazının bu bölümünde her iki host üzerinde Corosync’i yapılandıracağız. Bunun için öncelikle templatten bir conf dosyası oluşturalım:
Her iki node’da:
# cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
Sonra da aşağıda bold ve kırmızı olarak gösterilen alanları kendimize göre düzenleyelim:
# Please read the corosync.conf.5 manual page
compatibility: whitetank
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: 10.1.1.0
mcastaddr: 226.94.1.1
mcastport: 5405
ttl: 1
}
}
logging {
fileline: off
to_stderr: no
to_logfile: yes
to_syslog: yes
logfile: /var/log/cluster/corosync.log
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
Dosya içerisindeki bindnetaddr ibaresi iletişimin multicast olması dolayısı ile benim IP networkum başlangıcını işaret etmekte. (10.1.1.0). Bu parametreyi kendi ip networkünüzü belirtecek şekilde düzenleyin.
İkinci dikkat edilmesi gereken nokta ise mcastaddr parametresidir, buradaki corosync yapılandırması multicast olduğu için multicast adresini burada belirliyoruz ve her pacemaker cluster’ı için bu adresin eşsiz (uniq) olması gerekmektedir. Networkünüzde iki pacemaker cluster’ı var ise ve multicast haberleşiyorsanız, mcastaddr parametresinin her iki cluster için de aynı olması clusterların birbirlerinin iletişimlerine karışacakları anlamına gelmektedir. Bu nedenle ikinci bir cluster kurarsanız mcastaddr parametresini 226.94.1.1 yerine mesela 226.93.1.1 vermeniz gerekir. Bu konu ile ilgili detaylı bilgiye http://clusterlabs.org/doc/fr/Pacemaker/1.1-crmsh/html/Clusters_from_Scratch/_sample_corosync_configuration.html adresinden erişebilirsiniz.
Son olarak gene her iki host’ta /etc/corosync/service.d/pcmk isimli bir dosya oluşturuyoruz:
Her iki node’da:
vi /etc/corosync/service.d/pcmk
ve içerisine aşağıdaki ibareleri ekliyoruz:
service {
# Load the Pacemaker Cluster Resource Manager
name: pacemaker
ver: 1
}
Bu şekilde Corosync yapılandırması tamamlanmış oluyor.
Pacemaker Yapılandırması
Bu aşamada Pacemaker’ı DRBD ve MySQL servislerini yönetmesi için yapılandıracağız. Bu işlem için crmsh isimli pacemaker yapılandırma aracını kullanacağız. Ancak bu araç base paket depolarında bulunmadığından opensusre’nin reposundan kuracağız:
Her iki node’da:
# wget -O /etc/yum.repos.d/network:ha-clustering:Stable.repo http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-6/network:ha-clustering:Stable.repo
Repo’yu sadece bu paket için kullanacağımızdan disable edelim:
# sed -i s#enabled=1#enabled=0#g /etc/yum.repos.d/network\:ha-clustering\:Stable.repo
ve paketi yükleyelim:
# yum install crmsh --enablerepo=network_ha-clustering_Stable -y
Şimdi configuration tool yüklendiğine göre, pacemaker’ı yapılandırmaya başlayabiliriz.
Öncelikle her iki node üzerinde de corosync ve pacemaker’ı start ediyoruz.
Her iki node’da:
# /etc/init.d/corosync start # /etc/init.d/pacemaker start
Servislerin çalışmasından 30 sn sonra node’lar birbirlerinden haberdar hale geleceklerdir. Bunu görmek için nodelardan herhangi birinde aşağıdaki komutu çalıştırabilirsiniz:
# crm_mon -1 Last updated: Wed Jan 29 19:15:04 2014 Last change: Wed Jan 29 19:14:48 2014 via crmd on node01 Stack: classic openais (with plugin) Current DC: node01 - partition with quorum Version: 1.1.10-14.el6_5.2-368c726 2 Nodes configured, 2 expected votes 0 Resources configured Online: [ node01 node02 ]
Yukarıdaki çıktıda görüldüğü üzere 2 node online durumda görünüyor. Ancak henüz herhangi bir resource tanımlı değil.
Şimdi drbd ve mysql ile ilgli resource tanımlamalarımızı yapalım.
Yapacağımız ilk tanım cluster’a quorum policy’sini ignore etmesini söylemek. Bu quorum hadisesi, cluster içerisindeki nodeların kendi durumları ile ilgili cluster’a bilgi vermek için kullandıkları bir oylama sistemidir. Clusterdaki her node durumunu bildirir ve cluster’ın çalışabilmesi için yeterli node olup olmadığına bu sistem üzerinden karar verilir. Eğer yeterli sayı bulunamazsa cluster data/servis bütünlüğünü sağlamak için kendisini shutdown eder. Örnek olarak 3 node’dan oluşan bir cluster’da node’lardan birinin down olması durumunda, quorum sonucu 2’ye 1 aktif node tespit edileceğinden dolayı pacemaker hayatına iki node ile devam edebileceğine karar verip sürekliliği sağlayabilir. Ancak bizim yapımızda sadece iki node olduğundan ve node’lardan birinin down olması (ben buradayım diye oy kullanamaması) durumunda çoğunluk sağlanamayacağından dolayı pacemaker hayatta kalan node’u da shutdown edecektir. Bu yapmaya çalıştığımız yüksek erişilebilirlik senaryosuna ters olduğu için bu quorum policy’sini ignor edeceğiz. (Biz bu ignore ettiğimiz bu özellik yerine, yazının ilerleyen bölümünde sorunlu node’ların -data’ya zeval vermemeleri için- kendi kendilerini kapatmalarını sağlayacak bir network kontrolü uygulayacağız.)
Sadece node01’da:
crm configure property no-quorum-policy=ignore
İkinci tanımlama ise, hangi resourceların nodelar arasında ne zaman migrate edileceğinin belirleyen resource_stickness parametresidir. Örnek olarak özellikle belirli bir resource’u özellikle belirli bir node üzerinde çalıştırmak istediğiniz zaman faydalı olabilen bu özellik bizim iki adet birbirine eş node kullanıyor olmamızdan dolayı çok önem arzetmiyor; bu nedenle default olarak 100 olarak set ediyoruz. (Aslında bu konu biraz karışık ve yukarıdaki açıklama tam yeterli değil. Detay için pacemaker dökümanlarına bakmanızı tavsiye ederim.
crm configure rsc_defaults resource-stickiness=100
Bir diğer tanımlama ise “fencing” diye de bilinen STONITH (Shoot The Other Node In The Head) özelliğini disable etmektir. Bu özellik node’ların arızalandığı düşünülen diğer bir node’u split-brain gibi istenmeyen durumlara neden olmaması için shutdown etmelerini sağlayan bir özelliktir. Ancak bizim sadece iki node’umuz olduğu ve node’ları kendi connectivitylerini kontrol edip sorun olması halinde kendi kendilerini durdurmaları üzerine yapılandıracağımız için STONITH’i kapatıyoruz:
crm configure property stonith-enabled=false
Şimdi, pacemaker’ın yöneteceği resource’ları tanımlayacağız. Bunun için -drbd servisinin yönetimini pacemaker’a vereceğimizden dolayı- her iki node üzerinde drbd servisini durduruyoruz:
Her iki node’da:
# /etc/init.d/drbd stop
Sonra da node01 üzerinde pacemaker’ı yapılandırma işlemine başlıyoruz. (node01 üzerinde yapılan tanımlamalar diğer node’a da uygulanacağı için bu işlemi sadece bir node üzerinde yapacağız.)
Sadece node01’da:
Aşağıdaki komut ile pacemaker komut satırına bağlanıyoruz:
# crm configure
ve bizim clusterdb isimli DRBD resource’umuzu yönetecek p_drbd_mysql isimli bir primitive resource tanımlıyoruz:
primitive p_drbd_mysql ocf:linbit:drbd params drbd_resource="clusterdb" op monitor interval="15s"
Sonrasında ise sadece 1 adet master’a izin veren bir master-slave relationship’i tanımlıyoruz:
ms ms_drbd_mysql p_drbd_mysql meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
Ardından, pacemaker’ın /dev/drbd0 diskini /mysql_drbd dizinine ext4 filesystem’i ile mount etmesi için pf_fs_mysql isimli bir primitive resource daha tanımlıyoruz:
primitive p_fs_mysql ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/mysql_drbd" fstype="ext4"
Tanımlayacağımız bir diğer resource ise master’a atanacak olarak Virtual IP’yi set eden p_ip_mysql isimli resource. (Not: Bold ve kırmızı olarak işaretli olan IP’yi kendinize göre düzenlemeyi unutmayın.)
primitive p_ip_mysql ocf:heartbeat:IPaddr2 params ip="10.1.1.100" cidr_netmask="24" nic="eth0"
Sonra da pacemaker’ın mysql’i nasıl başlatacağını söyleyen p_mysql isimli bir resource tanımlıyoruz: (Not: Bold ve kırmızı olarak işaretli olan MySQL –bind-address= parametresine kendi VIP’inizi eklemeyi unutmayın.)
primitive p_mysql ocf:heartbeat:mysql params binary="/usr/libexec/mysqld" config="/mysql_drbd/my.cnf" user="mysql" group="mysql" datadir="/mysql_drbd/data" pid="/var/lib/mysql/mysql.pid" socket="/var/lib/mysql/mysql.sock" additional_parameters="--bind-address=10.1.1.100" op start timeout="120s" interval="0" op stop timeout="120s" interval="0" op monitor interval="20s" timeout="30s"
Böylece, p_drbd_mysql, p_fs_mysql, p_ip_mysql, p_mysql olmak üzere temel resourceları tanımlamış olduk.
Şimdi de, MySQL servisinin başlatılabilmesi için elzem olan p_fs_mysql p_ip_mysql p_mysql isimli resource’ları g_mysql ismi ile gruplayacağız.
group g_mysql p_fs_mysql p_ip_mysql p_mysql
Sonrasında da g_mysql grubunun DRBD master üzerinde çalıştırılmasını söyleyeceğiz. Bu şekilde g_mysql isimli (virtual ip, mysql_drbd dizinini ve mysql servisinin kendisini içeren) grup DRBD’nin master (Primary) olduğu node’da çalıştırılacak ve bu grubun çalışması için DRBD’nin çalışıyor olma koşulu aranacak:
colocation c_mysql_on_drbd inf: g_mysql ms_drbd_mysql:Master order o_drbd_before_mysql inf: ms_drbd_mysql:promote g_mysql:start
Temel tanımlamalar bu kadar. Şimdi konfigurasyonun devreye alınması için commit diyoruz:
commit
commit dediğiniz zaman timeout değerleri ile ilgili aşağıdaki gibi bildirimler alabilirsiniz:
WARNING: p_fs_mysql: default timeout 20s for start is smaller than the advised 60 WARNING: p_fs_mysql: default timeout 20s for stop is smaller than the advised 60 WARNING: p_drbd_mysql: default timeout 20s for start is smaller than the advised 240 WARNING: p_drbd_mysql: default timeout 20s for stop is smaller than the advised 100 WARNING: p_drbd_mysql: action monitor not advertised in meta-data, it may not be supported by the RA
Ancak timeout değerleri Oracle’ın dökümanında belirtildiği şekliyle verildiği için bu warning’leri ignore edebilirsiniz.
Son olarak crmsh’dan exit komutu ile çıkıyoruz:
exit
Şimdi cluster temel hatları ile kurulmuş ve çalışıyor olmalıdır. Durumu kontrol etmek için aşağıdaki komut ile clustr durumunu monitor edelim:
# crm_mon -1
Herşey yolunda gittiyse çıktı şu şekilde olmalıdır:
Last updated: Wed Jan 29 20:37:37 2014
Last change: Wed Jan 29 20:28:57 2014 via cibadmin on node01
Stack: classic openais (with plugin)
Current DC: node01 - partition with quorum
Version: 1.1.10-14.el6_5.2-368c726
2 Nodes configured, 2 expected votes
5 Resources configured
Online: [ node01 node02 ]
Master/Slave Set: ms_drbd_mysql [p_drbd_mysql]
Masters: [ node01 ]
Slaves: [ node02 ]
Resource Group: g_mysql
p_fs_mysql (ocf::heartbeat:Filesystem): Started node01
p_ip_mysql (ocf::heartbeat:IPaddr2): Started node01
p_mysql (ocf::heartbeat:mysql): Started node01
Bold alanlardan gördüğünüz gibi 2 node’dan oluşan cluster’ımızda 5 adet resource var ve g_mysql isimli filesystem, ip adres ve mysql’in kendisinden oluşan servis grubu node01 üzerinde çalışıyor.
Şu durumda, node01 üzerinden direk olarak mysql erişebiliyor olmanız gerekiyor. Aynı şekilde 10.1.1.100 isimli VIP üzerinden de erişebiliriz ancak öncesinde o ip’ye mysql üzerinden izin vermemiz gerekiyor
# mysql -u root -e "GRANT ALL ON *.* to 'root'@'%'"
Şimdi root kullanıcısı ile heryerden erişilebileceği için herhangi bir node üzerinden doğrudan VIP’ye bağlantı deneyebiliriz:
~]# mysql -h 10.1.1.100 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 5 Server version: 5.1.71 Source distribution Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
Hazır MySQL bağlantısı sağlanmışken test için bir de db açalım:
CREATE DATABASE clusterdb; USE clusterdb; CREATE TABLE simples (id INT NOT NULL PRIMARY KEY); INSERT INTO simples VALUES (1),(2),(3),(4);
Herşey yolunda gittiyse cluster’ımız çalışıyor demektir. Bunun testlerini yapacağız ancak öncesince konfigurasyon açısından yapılması gereken bir iki iş daha bulunuyor.
Bizim kurduğumuz gibi yapılarda meydana gelebilecek split-braind diye tabir edilen olay, özellikle MySQL gibi data ile alakalı çalışan yapılar için en istenmedik durumdur. Kısaca iki node’un arasındaki bağlantının kopması sonucu her iki hostun’da (uzak host down oldu diye düşünüp) kendisini Master ilan etmesi sonucu ortamda iki adet Master olması gibi aslında hiç olmaması gereken bir senaryonun cereyan etmesidir.
Özellikle DRBD kullanılan bizim yapımızda böyle bir durum cereyan eder ve hostlara uygulamanızdan erişilmeye devam edip disklere veri girişi/çıkışı olursa, DRBD bağlantı probleminden dolayı senkronizasyon yapamayacağı gibi bağlantı durumunun düzelmesinin ardından da artık eş olmayan verilerden hangisinin primary hangisinin secondary olduğunu bilmediğinden dolayı diskleriniz inconsistent duruma gelecektir. Bu durumda yapacağımız işlem hangi diskteki verinin daha güncel olduğuna karar vermek ve diğer diskteki veriyi uçurup güncel olandan senkronize edilmesini sağlamaktır. Bu işleme bir victim seçmek de deniyor.
Velhasıl bu senaryonun hiç cereyan etmemesi için atacak kurşunumuz var elbette. Normalde bu gibi önlemler bizim yazının başında disable ettiğimiz STONITH mekanizması ile çözülüyor. Ancak bu fencing çözümü çok node’lu yapılar için kullanışlı olduğundan biz kullanamıyoruz. Bunun yerine pacemaker’a node’larımız üzerinden uzak bir hostu pinglemesini (örneğin gateway’imiz) ve belirli bir süre cevap alamazsa ilgili node’un shutdown etmesini söyleyeceğiz.
Bunun için öncelikle tekrar crm configure diyerek crm shell’ine erişelim:
# crm configure
ve p_ping isimli gateway’imizi işaret eden bir resource ekleyelim: (Burada kendi gateway ip’nizi girmeyi unutmayın.)
primitive p_ping ocf:pacemaker:ping params name="ping" multiplier="1000" host_list="10.1.1.1" op monitor interval="15s" timeout="60s" start timeout="60s"
sonra da p_ping resource’unun her iki hostta da eş zamanlı çalışması için kendisini node’ların ikisine de clone’layalım:
clone cl_ping p_ping meta interleave="true"
Son olarak da ping sonuçlarına göre aksiyon alacak kural dizimizi girelim:
location l_drbd_master_on_ping ms_drbd_mysql rule $role="Master" -inf: not_defined ping or ping number:lte 0
en sonunda da commit edip exit diyelim:
commit exit
Bu noktada ben gateway üzerinden ping testi yapmayı uygun buldum ama aslında bu durum network yapısına göre değişiklik gösterebilir. Bu nedenle pinglenecek mecrayı kendi network yapınızı göz önünde bulundurarak seçmenizi öneririm. Örnek olarak node’larınızın birbirlerine gatewaylerine gittikleri switch’ten başka bir switch üzerinden bağlı ise bu durumda ortak switch’lerini pinglemeyi tercih edebilirsiniz. Ben gateway senaryosunda, gateway’in gitmesi durumunda node’lar arasındaki iletişimin de duracağını varsayıyorum.
Az Rastlanır bir SB Senaryosu:
Bu kısımda anlatacağım durum, yukarıdaki gibi yapmanızın elzem olduğu bir durum değil. Ancak böyle bir ihtiyacınız olursa izleyebileceğiniz bir yoldur.
Bunun dışında ping testini yaptığınız host’un erişilebilir olması fakat node’ların birbirlerine erişmesinde problem olması gibi az rastlanabilecek bir durum söz konusu olursa DRBD’nin split-brain önlemek için kullandığı handler mekanizmasından da yararlanabilirsiniz. Kısaca drbd senkronizasyonunda (pacemaker’dan bağımsız olarak) bir split brain tespit edilirse aksiyon olarak kendi custom scriptlerinizi çalıştırabiliyorsunuz. Bizim örneğimizde handler’ınız mysql erişimini engelleyen bir iptables kuralı olabilir. Bu durumda split brain tespit edildiği an mysql üzerinden diske bir şey yazılıp çizilmemesini garanti etmiş olursunuz.
Bu işlem için her iki node’da /etc/drbd.d/clusterdb.res dosyasını açın:
Her iki node’da:
# /etc/drbd.d/clusterdb.res
ve handlers parantezinin içerisine şu satırı ekleyin:
split-brain "/sbin/iptables -A INPUT -p tcp --dport 3306 -j DROP";
Bu satırı eklediğinizde ilgili alan şu şekilde görünmelidir:
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
split-brain "/sbin/iptables -A INPUT -p tcp --dport 3306 -j DROP";
}
Böylece yukarıda anlattığım senaryoda drbd mysql’e bir şey yazılıp çizilmesine engel olacaktır.
Son İşlemler
Tanımlamalar ile ilgili yapılacaklar bunlardı. Şimdi, sistem açılışlarında pacemaker ve corosync’in başlatılmasını, -pacemaker tarafından yönetileceği için de- drbd ve mysql servislerinin başlatılmamasını söyleyelim:
Her iki node’da:
chkconfig drbd off chkconfig corosync on chkconfig mysqld off chkconfig pacemaker on
TEST
Cluster’ın doğru çalışıp çalışmadığını anlamanın en kolay yolu, crm_mon komutu hangi node’un master olduğunu tespit edip, ilgili node’eu restart etmektir. Örnek olarak node01 master ise bu node’u restart ettiğiniz zaman bir kaç saniye içerisinde tüm servisler node02 üzerinde up edilecektir. Bunu node01 restart olurken node02 üzerinde crm_mon ile durum kontrolü yaparak gözlemleyebilirsiniz.
Öte yandan resource’ları hostlar arasında manual olarak da taşımanız mümkündür. Misal olarak node01 üzerinde çalışan g_mysql isimli resource grubumuzu node02’ye aşağıdaki komut ile migrate edebiliriz:
# crm resource migrate g_mysql node02
Bu komutu verdiğiniz zaman daha önce Master olan node01 Slave olacak, node02 Master olarak set edilecektir. crm_mon çıktısında durumu aşağıdaki gibi görebilirsiniz:
Last updated: Thu Jan 30 01:40:51 2014
Last change: Thu Jan 30 01:40:40 2014 via crm_resource on node01
Stack: classic openais (with plugin)
Current DC: node01 - partition with quorum
Version: 1.1.10-14.el6_5.2-368c726
2 Nodes configured, 2 expected votes
7 Resources configured
Online: [ node01 node02 ]
Master/Slave Set: ms_drbd_mysql [p_drbd_mysql]
Masters: [ node02 ]
Slaves: [ node01 ]
Resource Group: g_mysql
p_fs_mysql (ocf::heartbeat:Filesystem): Started node02
p_ip_mysql (ocf::heartbeat:IPaddr2): Started node02
p_mysql (ocf::heartbeat:mysql): Started node02
Clone Set: cl_ping [p_ping]
Started: [ node01 node02 ]
Yalnız manual olarak migration işlemi yaptıktan sonra kontrolü mutlaka aşağıdaki komut ile cluster’a geri vermeniz gerekir.
# crm resource unmove g_mysql
Aksi halde Master herzaman node02 olarak set edilmeye çalışılacaktır. Örnek olarak master şu anda node02 ise, node02’yi restart ettiğiniz zaman resource’lar node01’e göçecek ancak node02 açıldığı zaman tekrar node02’e dönecektir. Fakat çok fazla migration işlemi özellikle MySQL gibi doğrudan data ile alakalı işlerde çok da istemediğimiz bir şeydir. Bu nedenle manual olarak migration yaptıktan sonra yukarıdaki komutu kullanarak kontrolü mutlak olarak cluster’a geri vermeniz gerekir.
Manual Split Brain Recovery
DRBD’de split brain tespit edilirse yapılandırma gereği DRBD uzak host ile olan bağlantısını koparacaktır. Bu durumda uzak hostun disk sync durumu bilinemeyecek ve sizden manual olarak sync işlemi yapmanız istenecektir. Bu durumda hangi diskteki verinin daha yeni olduğuna karar vermeniz ve öteki diskteki veriyi uçurup, güncel veriyi tutan node’dan sync başlatmanız gerekecektir. Bu işlemin nasıl yapılacağı detayları ile birlikte aşağıdaki linkte anlatılmakta. Data discard etmek gibi tehlikeli işler içerdiğinden dolayı ben özellikle burada şu şu komutları çalıştırın demeyeceğim. Onun yerine böyle bir durum söz konusu olursa aşağıdaki resmi drbd dökümanından faydalanmanızı tavsiye ederim.
http://www.drbd.org/users-guide/s-resolve-split-brain.html
Bu yazılar da ilginizi çekebilir:
- MySQL Replication durumunu bir script ile check etmek
- Mysql Replikasyon Yapılandırması
- Mysql Root Şifresini Resetlemek – Password Recovery
- MySQL – Stored Procedure ve Function’ların Yedeklenmesi
- Lighttpd, Mysql, Php, Eaccelerator ile OpenAds Ad Server kurulumu.
Yorumlar
Trackbacks
Yorumda bulunun.
Merhaba.
Yazınızı çok başarılı buldum. Oracle tarafından yayınlanan Mysql-Corosync-Pacemaker kılavuzunda bir bir çok hata var. Bu çok daha süzülmüş, kontrol edilmiş bir yazı ve çok faydalı.
Bir nokta dikkatimi çekti. pacemaker ve corosync’i auto-start yapma komutlarını eklemediğiniz için sunucular reboot edildiğinde servisler başlamıyor ve hizmet devreye girmiyor. Belki de bunu da eklemek iyi olabilir.
iyi çalışmalar.
Tekrar merhaba ;
CentOS 6.5 kullanıyorum. Dün itibariyle paket güncellemesi yaptıktan sonra bu yordamı takip ettim ancak aşağıdaki hatayı alıyorum. Yorumunuz var mı ?
Online: [ node-01 ]
OFFLINE: [ node-02 ]
Master/Slave Set: ms_drbd_mysql [p_drbd_mysql]
Masters: [ node-01 ]
Stopped: [ node-02 ]
Resource Group: g_mysql
p_fs_mysql (ocf::heartbeat:Filesystem): Started node-01
p_ip_mysql (ocf::heartbeat:IPaddr2): Started node-01
p_mysql (ocf::heartbeat:mysql): Stopped
Failed actions:
p_mysql_start_0 on node-01 ‘unknown error’ (1): call=45, status=complete, last-rc-change=’Mon Jun 9 16:48:47 2014′, queued=231ms, exec=0ms
Merhabalar,
Bilgilendirmeniz için teşekkür ederim. Notlarım arasına aldım; bu noktaları da ekleyeceğim.
Selamlar,
mySQL’i start edememiş. Bunun birden çok sebebi olabiliyor; tüm logları satır satır inceleyebilirseniz sorunun nedenini yakalayabilirsiniz sanıyorum. Buradan paylaşabilirseniz beraber de bakabiliriz.
yazma yogun mysql database lerinde servisin bir node dan digerine gecmesi esnasında rame alınmız ama henuz database e yazılmamıs veri icin bir koruma yontemi sanırım bu topolojide sorun cıkartacaktır. ozellikle yazma yogun database ler icin master-master calısan ve 2 data node u olan bir mysql cluster daha verilmli olmayacakmıdır?
Evet, yazma yoğun sistemler için doğrudan mySQL clustering daha doğru gibi ancak bu senaryoda data kaybından ziyade node’lar arasında geçiş (yaklaşık 5 sn) boyunca DRBD bloku unresponsive olduğundan servis verememe durumu meydana geliyor. Bir de bazı split-brain senaryoları var ki o durumda data kaybı da söz konusu olabilir.
node lar arasındaki gecisteki servis kesintisi zaten yapının genel karakteristigi . benim dikkat cekmek istedigim nokta cesitli senaryolarda mysql sunucusuna yazılmak icin ram de bekleyen verinin node lardan o an aktif olanının standart dısı bir sebeple ulasılmaz olması durumunda sıkıntı cıkartabilecegine dikkat cekmekti. aktif node u reboot etmek , yada o node uzerinde mysql servisinin yonetici marifeti ile durdurulması zaten mysql in standart durma proseduru ile olacagından ramdeki bilgi veritabanına yazılacak ve servis diger noda aktarılacaktır. ancak aktif node un ornegin bir elektrik sorunu sebebi ile ani kapanması yada sunucu isletim sistemi uzerindeki sorun sebebi ile kilitlenmesi durumunda ( misal ram ve swap alanının tukenerek durması yada olası baska sebepler) mysql tarafından ram de bekletilen ve henuz disk uzerine yazılması bitmemis verinin kaybolması sonucunu dogurabilir. tabiki bu senaryo oldukca ektrem bir durumu ozetliyor.
split-brain taradı zaten sizin yazınızdada onbilgi olarak acılmanmıs durumda ve bu durumlar icin cesitli onlemler alabilmekte olası.
2 node uzerinde master-master calısan bir gercek mysql clusteri ( ki ozellikle dusuk butceli durumlarda cluster master node unun uzerinde aynı zamanda data node u da calıstırmak mumkun olmakta. cluster master larının ram lerinin de surekli senkronize durumda buluması bakımından bir miktar daha guvenli geliyor bana. tabiki mysql cluster master node ları icin database buyuklukleri ile orantılı ram gerekliligi doguyor ki bu durum ozellikle cok database barındıran ( misal web hosting mysql sunucuları icin ) zaman zaman kaynak sıkıntıları dogmasına sebep olabilmekte.
ben sadece servisin birkac saniye kesilmesi yanında anlık olarak ramde duran verinin kaybedilmesinin sıkıntı dogurabilecegi senaryolar olabilecegine dikkat cekmek istemistim.
DRBD ile MySQL servisi üzerinde clustering hafiften “poor man’s cluster” olduğundan spesifik durumlar ve kritik noktalarda kullanmak için pek de doğru değil bence de.
Merhaba yazınınz harika, bir yerde yazım hatasınından ilerleyemiyorum en sonki durumum aşağıdaki gibi ama crm de aşağıdaki komur sytax hatası veriyor acaba neresi hatalı yardımcı ols-rsan mütkiş olacak. Yeni yazılarında başarılar.
crm(live)configure# primitive p_ping ocf:pacemaker:ping params name=”ping” multiplier=”1000″ host_list=”10.99.99.1″ op monitor interval=”15s” timeout=”60s” start timeout=”60s”
ERROR: syntax in primitive: Unknown arguments: start timeout=60s near parsing ‘primitive p_ping ocf:pacemaker:ping params name=ping multiplier=1000 host_list=10.99.99.1 op monitor interval=15s timeout=60s start timeout=60s’
[root@node01 ~]# crm_mon -1
Last updated: Wed Dec 31 00:17:42 2014
Last change: Tue Dec 30 16:01:44 2014
Stack: classic openais (with plugin)
Current DC: node01 – partition with quorum
Version: 1.1.11-97629de
2 Nodes configured, 2 expected votes
5 Resources configured
Online: [ node01 node02 ]
Master/Slave Set: ms_drbd_mysql [p_drbd_mysql]
Masters: [ node01 ]
Slaves: [ node02 ]
Resource Group: g_mysql
p_fs_mysql (ocf::heartbeat:Filesystem): Started node01
p_ip_mysql (ocf::heartbeat:IPaddr2): Started node01
p_mysql (ocf::heartbeat:mysql): Started node01
start timeout=”60s” yazmayınca hata almadım
Evet sorunu buldum,
primitive p_ping ocf:pacemaker:ping params name=”ping” multiplier=”1000″ host_list=”10.90.1.3″ op monitor interval=”15s” timeout=”60s” op start timeout=”60s”
op yazmak gerekiyor.
Kolaygelsin
Merhaba,
Node1 de
Failed actions:
p_drbd_mysql_promote_0 on node01 ‘unknown error’ (1): call=101, status=Timed Out, last-rc-change=’Wed Dec 31 10
:26:36 2014′, queued=0ms, exec=20001ms
böyle bir hata oluyor gerçi sunucuları reboot ettiğimde geçişleri sorunsuz oluyor ping sürekli vip atılabiliyor ve mysql sürekli çalışıyor. Sadece hatanın sebebini anlayamadım?
Node01
Last updated: Wed Dec 31 10:48:58 2014
Last change: Wed Dec 31 10:14:07 2014
Stack: classic openais (with plugin)
Current DC: node01 – partition WITHOUT quorum
Version: 1.1.11-97629de
2 Nodes configured, 2 expected votes
7 Resources configured
Online: [ node01 ]
OFFLINE: [ node02 ]
Master/Slave Set: ms_drbd_mysql [p_drbd_mysql]
Masters: [ node01 ]
Stopped: [ node02 ]
Resource Group: g_mysql
p_fs_mysql (ocf::heartbeat:Filesystem): Started node01
p_ip_mysql (ocf::heartbeat:IPaddr2): Started node01
p_mysql (ocf::heartbeat:mysql): Started node01
Clone Set: cl_ping [p_ping]
Started: [ node01 ]
Stopped: [ node02 ]
Failed actions:
p_drbd_mysql_promote_0 on node01 ‘unknown error’ (1): call=101, status=Timed Out, last-rc-change=’Wed Dec 31 10
:26:36 2014′, queued=0ms, exec=20001ms
Node2
Last updated: Wed Dec 31 10:48:51 2014
Last change: Wed Dec 31 10:35:26 2014
Stack: classic openais (with plugin)
Current DC: node02 – partition WITHOUT quorum
Version: 1.1.11-97629de
2 Nodes configured, 2 expected votes
5 Resources configured
Online: [ node02 ]
OFFLINE: [ node01 ]
Master/Slave Set: ms_drbd_mysql [p_drbd_mysql]
Masters: [ node02 ]
Stopped: [ node01 ]
Resource Group: g_mysql
p_fs_mysql (ocf::heartbeat:Filesystem): Started node02
p_ip_mysql (ocf::heartbeat:IPaddr2): Started node02
p_mysql (ocf::heartbeat:mysql): Started node02
İkiside kendisini master sanıyor.
ve
[root@node01 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.5 (api:1/proto:86-101)
GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by phil@Build64R6, 2014-10-28 10:32:53
m:res cs ro ds p mounted fstype
0:clusterdb StandAlone Primary/Unknown UpToDate/DUnknown r—– ext4
çıktısı veriyor ne yapmam lazım acaba yardımcı olabilirsen çok sebinirim…
OFFLINE: [ node02 ] ibaresinde bahsettiği gibi node02 offline görünüyor bu nedenle [root@node01 ~]# service drbd status çıktısında node02 için 0:clusterdb StandAlone Primary/Unknown UpToDate/DUnknow uyarısı alıyorsunuz.